Lekari su značajno nadmašili GPT-5 i pet drugih velikih jezičkih modela (LLM) u tumačenju snimaka pozitronske emisione tomografije/kompjuterizovane tomografije (PET/CT) izvođene uz primenu radiofarmaka fluor-18 fluorodeoksiglukoze (F-18 FDG) kod pacijenata sa karcinomom jednjaka, izvestila je grupa istraživača iz Japana.
U kolekciji od 120 snimaka odraslih pacijenata koji su bili podvrgnuti snimanju radi preoperativnog stejdžinga, četiri lekara različitog nivoa iskustva identifikovala su lokalizaciju tumora sa značajno većom preciznošću u poređenju sa LLM modelima, navodi se u studiji.
„Iako aktuelni LLM modeli još nisu dostigli nivo preciznosti lekara što se tiče stejdžinga, noviji modeli pokazuju potencijal u pružanju pomoći u pojedinim dijagnostičkim zadacima“, naveo je autor-korespondent Jošitaka Tojama, sa Univerziteta Tohoku u Sendaju, sa saradnicima. Studija je objavljena 23. februara u časopisu JMIR Cancer.
Ezofagektomija spada među najobimnije onkološke operacije, a optimalni ishodi lečenja u velikoj meri zavise od preciznog stejdžinga pomoću F-18 FDG-PET/CT snimanja, gde je ono dostupno. Međutim, interpretacija ovih snimaka je složena i vremenski zahtevna, a dodatni veliki problem predstavlja ozbiljan nedostatak kadra u radiologiji i hirurgiji, naveli su autori.
Napredovanje i evolucija multimodalnih LLM modela, koji mogu istovremeno da obrađuju i interpretiraju i tekst i slike, podigao je očekivanja u pogledu njihove potencijalne primene u složenim medicinskim zadacima. Stoga su u ovoj studiji autori procenjivali njihov potencijal u stejdžingu karcinoma jednjaka.
U eksperimentu je upoređevina efikasnost šest LLM modela (GPT-5, GPT-4.5, GPT-4.1, OpenAI-o3, OpenAI-o1 i GPT-4 Turbo) i četiri “ljudska čitača” – jednog specijaliste nuklearne medicine, jednog gastrointestinalnog hirurga i dva specijalizanta radiologije. Zadatak je obuhvatao procenu zahvaćenosti limfnih čvorova (klinički N stadijum [cN] ) i prisustva ili odsustva udaljenih metastaza (klinički M stadijum [cM]) na 120 F-18 FDG-PET snimaka.
Prema rezultatima, stopa tačne klasifikacije kretala se od 41/120 (34%) do 94/120 (78%) kod LLM modela i od 72/120 (60%) do 102/120 (85%) kod lekara, pri čemu su lekari imali statistički značajno bolje rezultate (p < 0,05) u proceni torakalnih limfnih čvorova, abdominalnih limfnih čvorova i cN stadijuma.
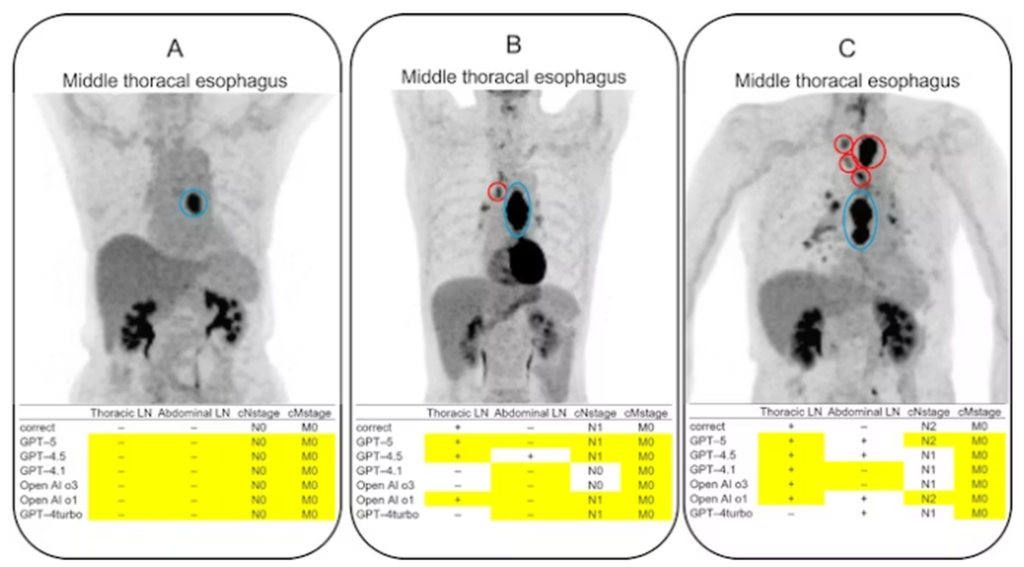
Izvor: JMIR Cancer
Među LLM modelima, GPT-5 je pokazao najvišu ukupnu stopu tačne klasifikacije. U poređenju sa starijim verzijama, noviji LLM modeli pokazali su se kao bolji u identifikaciji abdominalnih metastaza i cM stejdžingu, sa malo slabijom konzistentnosti pokazanoj pri cN stejdžingu. Na primer, u detekciji torakalnih metastaza u limfnim čvorovima, GPT-5 je ostvario 76/120 (63%) tačnih klasifikacija, dok su ostali modeli postigli 72/120 (60%) ili manje.
„Ovi statistički nalazi potvrđuju da, uprkos delimičnom preklapanju opsega preciznosti, aktuelni opšti LLM modeli zaostaju za ljudskim ekspertima u složenim zadacima stejdžinga karcinoma“, naveli su autori.
Ovi rezultati nisu neočekivani, niti predstavljaju iznenađenje. Budući da su LLM modeli primarno trenirani na tekstualnim podacima, oni se ističu u razumevanju i rezonovanju u jezičkom okruženju, ali za sada nemaju sposobnost pouzdane obrade i analize složenih vizuelnih informacija.
„Da bi se unapredila preciznost, buduća istraživanja trebalo bi da daju prioritet modelima koje bolje integrišu i tekstualne i vizuelne podatke. Uključivanje “učećih” multimodalnih sistema koji kombinuju tekstualne i slikovne informacije moglo bi da unapredi njihove dijagnostičke performanse i olakša njihovu kliničku primenu“, zaključili su autori.
Takav pristup omogućava standardizovane i reproduktibilne uslove testiranja, jer svi modeli dobijaju identične ulazne podatke i rade pod istim tehničkim podešavanjima. To je važno za objektivno poređenje njihovih performansi i za metodološku pouzdanost studije.
Pojašnjenje redakcije Pericardion-a: U ovoj studiji nije korišćen ChatGPT kakav ga većina nas poznaje kroz svakodnevnu upotrebu, već su različiti GPT i OpenAI modeli primenjeni kao istraživačka AI infrastruktura. Modeli su korišćeni putem programskog interfejsa (API), što znači da su im zadaci zadavani u tehnički kontrolisanom okruženju, sa unapred definisanim parametrima i bez interaktivnog „razgovora“ ili dodatnih instrukcija.
Napomena: Tekst predstavlja informativni prikaz objavljene naučne literature. Ne sadrži kliničke preporuke i ne može zameniti stručnu procenu lekara u realnim okolnostima.